

I must admit… I love languages. Beyond learning words and phrases in various languages, I love to learn how languages work. Yes, in addition to being a tech nerd, I’m also a language nerd.
Language is important. It’s how we (primarily) communicate. And, we’ve all been guilty of poor communication… even when communicating with someone who speaks the same language.
But, what about when communicating with a Large Language Model (LLM)? The LLM does not “speak” English. It communicates in numbers (usually tokens and vectors). In order to communicate with these LLMs, we convert words to tokens and vectors. This is how ChatGPT, Claude, Llama, etc are trained to “understand” English.
Then, when we want to provide additional information to the LLM beyond what they’ve been trained on, we can use various techniques such as Retrieval Augmented Generation (RAG).
 What is Retrieval Augmented Generation (RAG)?
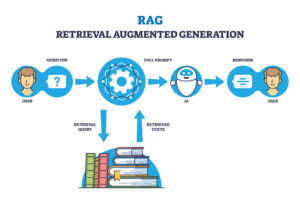
What is Retrieval Augmented Generation (RAG)?
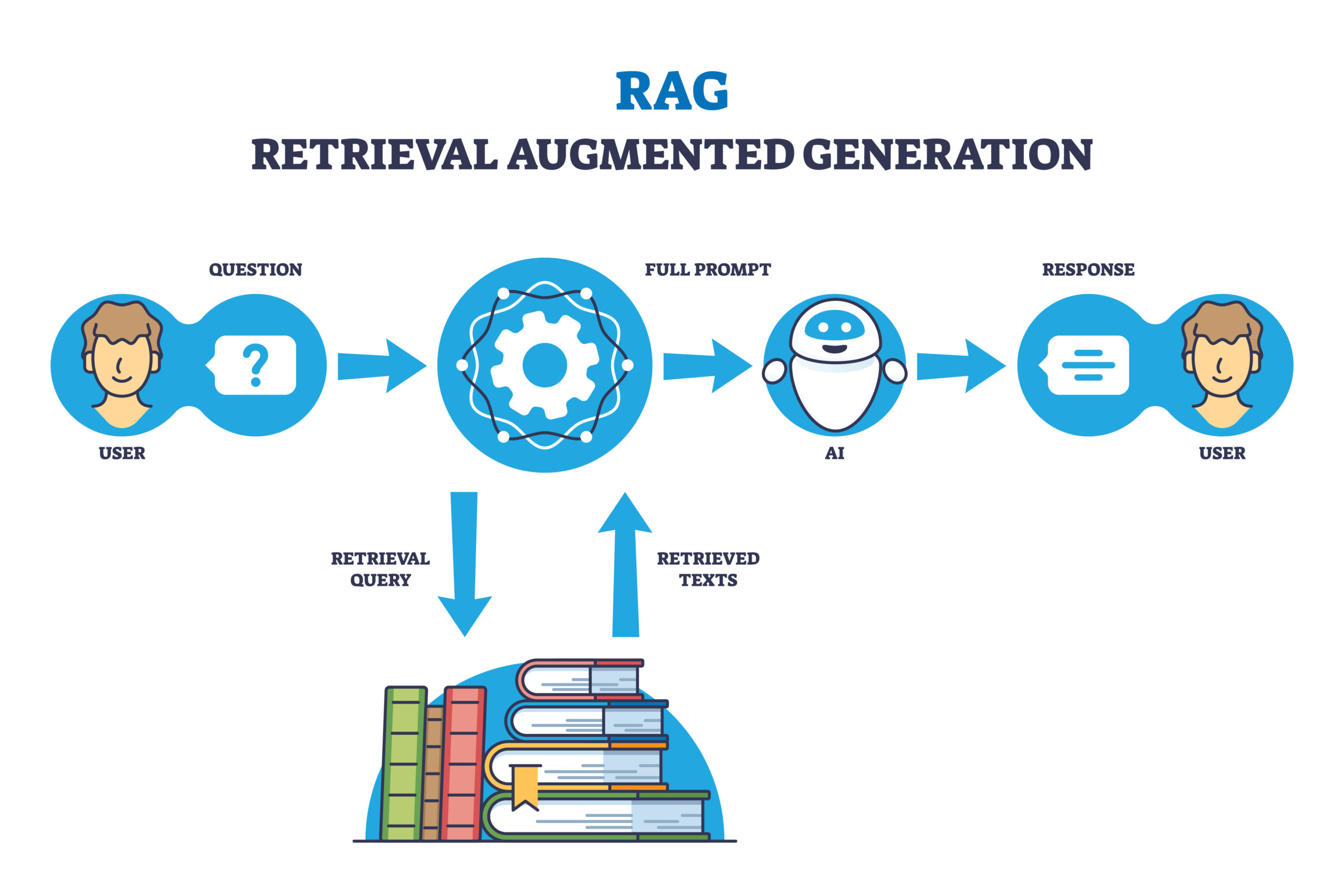
When someone wants to interact with a ChatBot (or other type of LLM) using data beyond their training data, one method is called Retrieval Augmented Generation (RAG). In RAG, besides sending the ChatBot the user’s prompt (question), you also send some relevant new information (context). This context could be recent news articles or research papers or even proprietary company information.
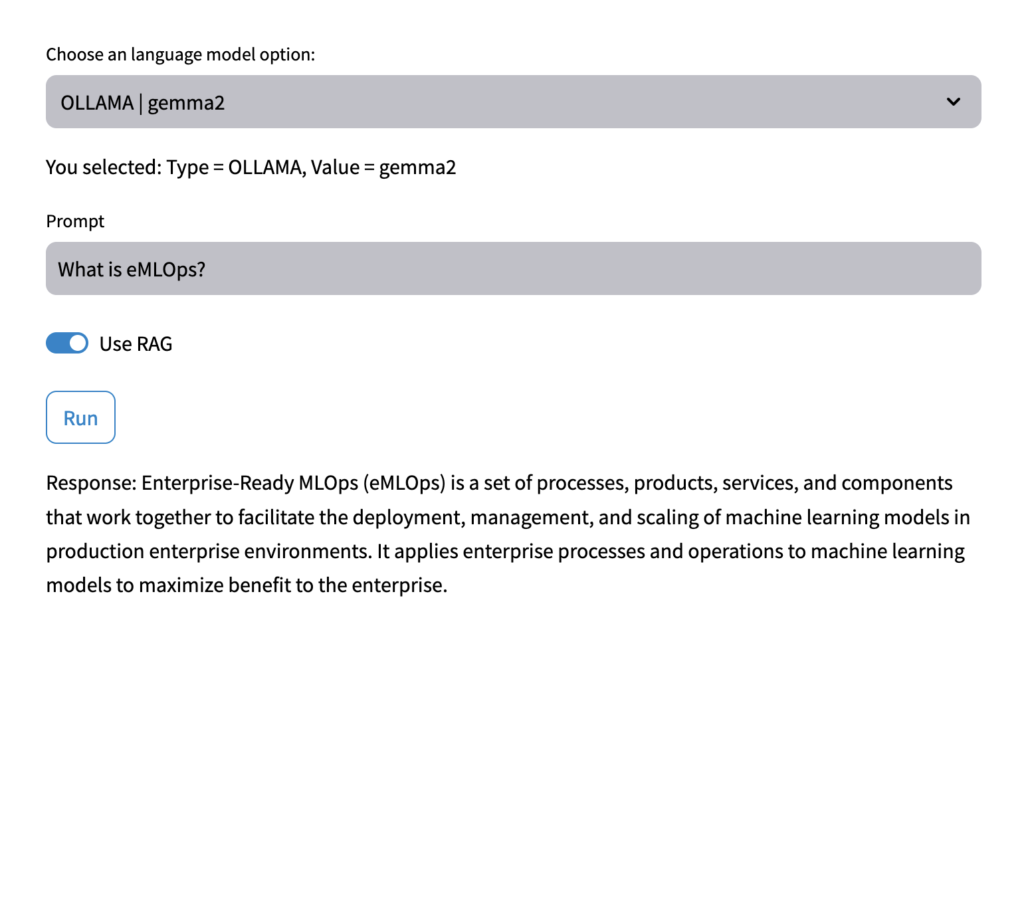
The ChatBot takes that new information into consideration when answering the question. For example, if I were to ask a ChatBot, “What is eMLOps?“, the ChatBot would not know, and would probably make up an answer (hallucination). However, if I also send the ChatBot copies of documents that CtiPath have published on eMLOps, the ChatBot would take those documents into account when answering the question, and would then be able to explain eMLOps.
This is called providing the LLM some “context”. See examples below:


The Problems with Context
Unfortunately, it’s not feasible to send the ChatBot an entire encyclopedia of new information each time you ask it a question about recent events or new products or services. For one thing, every LLM has a limit to the amount of information that you can send them at one time. Also, you pay for each token (similar to a word) that you send to an LLM. So, you only want to send “relevant” information.
In order to reduce the information sent to the LLM, the documents are usually broken down into pieces (chunks). These chunks are converted into numbers (vectors) and stored in a special database (vector database). Then, when a user asks a question, the question is also vectorized and the relevant chunks are returned from the vector db based on a search of the question (vectorized). Those smaller bits of (supposedly) relevant documents are then sent to the ChatBot as “context”.
So, what’s the problem? The problem is finding the best strategies to “chunk” your documents and store them into your vector db. The way the documents are chunked plays a big role in what information is sent to the ChatBot.
 Language Nerd Warning
Language Nerd Warning
This is where my language nerdiness rears its head.
You see, there are many ways to “chunk” documents. Some of the most popular ways include:
- Fixed Length (Token/Word-Based) Chunking – Split text based on a fixed number of tokens (e.g., 512 tokens) or words (e.g., 100 words). Works well for maintaining consistent embedding sizes but may cut off content mid-sentence or phrase.
- Sentence-Based Chunking – Split text into individual sentences or small groups of sentences. Keeps content coherent and improves the readability of chunks, which can enhance retrieval accuracy. However, sentences can vary in length, leading to inconsistent chunk sizes.
- Paragraph-Based Chunking – Divide text by paragraphs, keeping related information together in each chunk. This method is beneficial when documents are organized in a way where paragraphs represent discrete ideas or topics, but paragraphs may exceed token limits for some models.
In many cases, the “chunks” overlap in order to attempt to maintain context across chunks.
But, is this how language works? It’s true that “meaning” is found at the sentence and paragraph level. However, this meaning is only true within the larger context of a document or section of a document.
So a sentence meaning can be different if it’s placed within a different document.
Sending a group of words, or sentence, or even paragraph to a ChatBot does not mean that we are actually providing the meaning of that “chunk” to the ChatBot.
The question now becomes, “How do we provide meaning WITH the context?“
 How Do We Read and Understand Documents?
How Do We Read and Understand Documents?
In order to provide meaning WITH the contexts that we send to a RAG system, we must include the meaning in much the same way that we read documents.
When we start reading documents, we know the topic of the document. In fact, the topic is usually provided in the title or in the first few paragraphs of the document.
Next, as we read, we understand there are sections and subsections within the document.
So, a sentence or paragraph does not stand alone. The meaning of the sentence/paragraph if found within the topic of the document, section, and subsection. Or, as language nerds say, “Meaning is found IN the context.”
For documents, that meaning is found in the topics of the document, section, and subsection, not the titles. (Now, titles may be the same as topic, but we cannot assume they are the same.)
When we want to provide meaning with the “contexts” of the chunks we send to a RAG system, we must impute the document, section, and subsection topics within that chunk. Yes, that increases the token count (and thus perhaps increases the cost), but it also increases the retrieval accuracy when searching for relevant chunks. And, unless we provide meaning within the “contexts”, the retrieval process will not find the most relevant document chunks, and we won’t send the most relevant document chunks to the ChatBot.
How do we get the topics that we impute into the document “chunks” in order to provide meaning? There are several ways, but one of the most useful ways is to a employ an LLM that is designed to provide summarizations. (That brings up another question for a later article: Is it beneficial to provide a summary of a document or section as a “chunk”? So many questions, and so little time for this language nerd…)
 Conclusion
Conclusion
Think about a large spreadsheet with several columns and hundreds of rows. When you want to understand what’s going on in row 132, you can’t look at row 132 only. You also need to consider the header rows. The headers provide the context for the data in row 132.
In the same way, when we send text to a ChatBot in the form of a document chunk, we must also send the context. That context is found in the document, section, and subsection topic. Those topics need to be imputed into the chunk (in the same way that we “freeze” the header of a large spreadsheet).
Thus, when we add the topics to the chunk, we are providing meaning within the contexts.
In a future article, we’ll demonstrate how a tool that CtiPath developed for internal use allows us to test different chunking strategies to help our customers make intelligent decisions when deploying their Gen AI projects.
Ok… back to my study of languages and semantics and syntax…



