I like a good graphic tee as much as the next person. As I was preparing this article, I decided to buy a t-shirt imprinted with the article title. It would be a conversation starter, if nothing else.
I logged into my favorite online retailer, searched for the saying, and found one at a good price in the color that I wanted. After ordering, it arrived in only a couple of days.
Then I realized that one of the words was spelled incorrectly. Bummer. The retailer issued me a refund, and I searched for a replacement. This time, I checked the image carefully… only to find this one also had a word misspelled… a different word.
Probably created by AI, right?
This humorous (but true) story is an illustration of many people's responses to machine learning and AI. It sounds good in theory, but is often lacking in practice.
Hallucinations? LLM's delivering conspiracy theories? Employees sharing confidential information with open models?
We've all heard the horror stories…
What's the Problem?
Some of those that train models
Are the same that scale inference
There are many brilliant scientists and teams building state of the art (SOTA) machine learning models, and more are developed each day. So what's the problem?
There's an old computer support acronym called PEBKAC. It stands for "Problem Exists Between Keyboard and Chair", meaning the problem is with the user.
In the case of ML and AI, even ML experts recognize that PEBMAP: Problem Exists Between Model and Production.
"It's one thing to create a model that works inside a Jupyter notebook; it's a very different scenario to put it into a production system and then the production system uses the model to make decisions, solve business problems, and create revenue." – Noah Gift, Executive in Residence at Duke University
"The modeling is the easy part and it's the smallest percentage on the overall pipeline… but the other 90% of the work is operationalization, standards, practices, solutioning, how does it fit into the enterprise architecture." – Moritz "Mo" Steller, Microsoft
"Machine learning models are great, but unless you know how to put them into production, it's hard to get them to create the maximum amount of possible value." -Andrew Ng, Stanford University
"There's not – what I've seen at least – a ton or a plethora of enterprise ready use cases…" – Samuel Partee, Principal Applied AI Engineer at Redis
The ML experts agree. While Machine Learning has improved drastically in recent years, there has been little progress in deploying those State of the Art (SOTA) models into production, especially in enterprise environment.
Even Gartner recognizes that only 54% of machine learning models make it from the pilot or proof of concept stage to production. (In one year, that figure only increased by 1%, in spite of all the money and research being thrown at machine learning modeling.) In the same article, Gartner finds that 80% of executives think that ML automation can be applied to business decisions. But only half are seeing benefits of their ML development costs.
There is an answer to this problem…
SOTA Models Deserver SOTA MLOps
The problem is with MLOps (Machine Learning Operations).
While the state of ML modeling has improved drastically over the last few years, state of productionizing and operationalizing these models – especially in an enterprise environment – is still largely in the hobby stage. Yes, there are maturing tools to aid in deploying ML models for enterprise-readiness, but there are no single systems to handle the entire pipeline. And, if fact, there will probably never be a single system to handle the MLOps pipeline for enterprises.
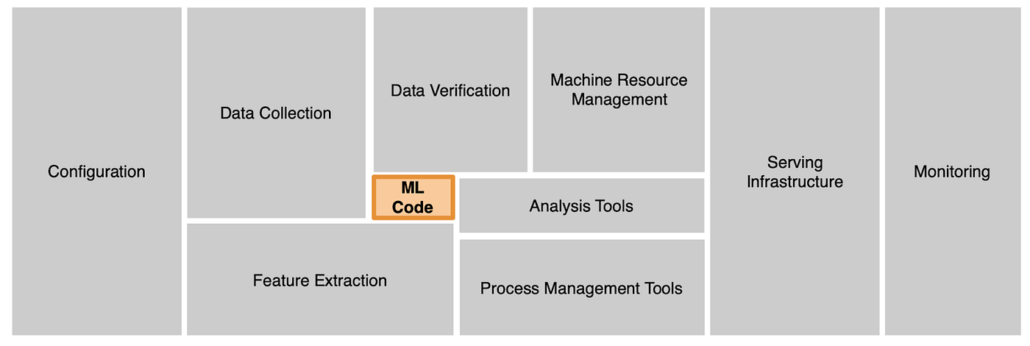
[D. Sculley et. al. NIPS 2015: Hidden Technical Debt in Machine Learning Systems]
Why? Because every enterprise is different, with different goals, different requirements, different systems, different methodologies, different governances… and a single system will never meet each of those unique parameters.
The problem is not with modeling. The problem is with deployment… and all the other building blocks that must be integrated together to provide a machine learning solution for the enterprise… for each enterprise.
Data scientists and researchers are great at training and validating ML models, and they're becoming better every day. However, it takes knowledge of enterprise computing infrastructures, procedures, systems, and processes to successfully deploy those models in enterprise environments.
The problem is that enterprises need a solution… not a product or service.
eMLOps: Enterprise-Ready MLOps
I recently purchased another graphic tee with the following inscription:
MLOps…
Because training the model is easy
Deploying it is not
Now, I don't agree with that statement. Training an ML model is not easy. Data scientists and ML enthusiasts spend years developing the knowledge and skills necessary to train a good ML model.
But when it comes to deploying, they often push the model behind an endpoint or API and call it a day. Or, they use a product that handles the deployment for them.
The problem is that this simplified version of model deployment will not work for enterprises. As I said earlier, enterprises do not need a product or service to deploy their ML models.
Instead, just as there is a set of knowledge and skills necessary to train a good ML model, there is a different set of knowledge and skills necessary to design a solution to deploy that model in an enterprise environment.
At CtiPath, we call that solution eMLOps: Enterprise-Ready MLOps.